I’ve been living this reality for a while now. Honestly, it’s felt like a bit of a professional “coming out” moment for me.
As a Senior IC, I carry this massive expectation to be the “guardian of the code.” But the truth is, I’ve almost entirely stopped looking at or reviewing code for months now. My workflow has completely flipped. Instead of writing and reviewing syntax, my process is now:
- Detailed Spec: Pouring all my energy into rigorous architectural requirements.
- Agent Execution: Letting the AI handle the implementation details.
- Validation: Manually testing to find issues — analogous to the exploratory testing we all do — and then generating automated tests to preserve the validated functionality.
I lived with the fear that if I admitted this, I would be judged as having lost my technical edge — that I would be a mere “Prompt Engineer” and not a Principal Engineer. I questioned if this made me an imposter.
I realized my vulnerability stemmed from an outdated metric of worth. Now, I am judging myself by a new standard: How fast am I enabling my Product Triad to experiment?
“I rapidly went from about 80% manual+autocomplete coding and 20% agents to 80% agent coding and 20% edits+touchups. I really am mostly programming in English now.” — Andrej Karpathy
“For me personally it has been 100% for two+ months now, I don’t even make small edits by hand… I think most of the industry will see similar stats in the coming months.” — Boris Cherny (Creator of Claude Code)
Seeing industry leaders echo this validates the shift. I need to stop being paranoid about AI writing code. I need to let go of the ego that feels the need to prove the AI is “wrong”. I have started treating software as disposable. My goal is to iterate fast, ship faster, test hypotheses faster, and find issues immediately. This isn’t “lazy” engineering — it is high-velocity architecture.
I’m not against code review
I want to be clear — I’m not against code review. But reading code line-by-line means I am just shifting the bottleneck from writing to reading. If AI writes code 10x faster but I still review every line, I haven’t sped anything up. The productivity gains die.
So I have been experimenting with what it means to not review code line-by-line. What is the right level of abstraction where I am comfortable with the human-in-the-loop to delegate to AI? I don’t have the final answer, I’m actively figuring this out, but I know that reading every line of AI-generated code is the wrong answer.
Here’s what my process looks like:
- Spec review — I align on what and why, and delegate the how completely to AI.
- High-level code checks — with the spec in mind, I know what sections to focus on and what should pop out.
- Manual testing — I validate the implementation conforms to the spec.
- Automated tests — AI writes tests to preserve the validated behavior.
Look at the levers. A bad line of code — that’s one bad line of code. A bad plan — that’s hundreds of bad lines of code. But a bad spec? That’s thousands of bad lines across the whole implementation. So where should I spend my review time? At the top. At the spec.
Why I moved away from TDD
One nuance I want to point out in that pipeline — I manually test before asking AI to write the tests.
I started with TDD — write the tests first, then implement. It’s a discipline I believed in deeply. But then I realized: if AI writes the tests, I have to review the tests. And reviewing tests is still reading code. I’m back to being the bottleneck.
So I switched the workflow. Implement first, do manual exploratory testing to validate that the behavior matches the spec, and then have AI write automated tests to preserve the behavior. This way I can iterate faster and also have a safety net of tests to catch regressions. The tests become a regression safety net, not a design tool — the spec is the design tool now.
This was uncomfortable. TDD was part of my identity as a disciplined engineer — another piece of identity I had to let go of. But the logic is the same as the code review shift: if reading code is the bottleneck, then any process that requires me to read AI-generated code — whether it’s implementation or tests — reintroduces the bottleneck.
The wrong question vs. the right question
The conversation I keep hearing is “Can we trust AI?” That’s a dead-end question — it’s a debate. The question that unlocks progress is “How do I start trusting AI?” When I flip from “can” to “how” it opens up possibilities and it becomes an engineering problem.
“Anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again.” — Mitchell Hashimoto
That’s the mindset. Not “can I trust AI” — but “how do I make it trustworthy.” I don’t fix the output, I fix the input. Better specs, better constraints, better context, better harness.
The autonomous driving parallel
I have seen over the years the mainstream media coverage of how autonomous driving technology is naive. But I am now living in reality — especially seeing Waymo in and around the Bay Area. AI coding resurfaces similar sentiment. I keep reading about how the database is wiped out, how the credentials are leaked, how counterintuitive the technology is and the tech debt it creates.
Early Tesla self-driving was controversial because it wasn’t perfect. There was a question: are people comfortable with this level of imperfection?
There are probably some tasks for coding agents where people will be comfortable with something that’s not perfect, something that needs to learn from its mistakes. There are some areas where people will not be comfortable. Are you comfortable with it occasionally breaking your code? Maybe — and maybe in a few years it will stop breaking, but in the meantime it’s not quite there. Are you comfortable with a coding agent in your project where there is money movement? Maybe not. And that’s okay.
Figuring out how those factors interact — what that means for the timeline, for how these systems get better with experience — that’s the tricky question. And as the technology evolves, I have to evolve with it. What I’m comfortable delegating today is not what I’ll be comfortable delegating six months from now. My workflow, my level of trust, my review process — all of it has to keep moving. But you won’t figure it out by debating in the abstract. You figure it out by experimenting.
Bringing the whole triad in
There’s a problem that already existed before AI coding agents — the 1:N impedance mismatch between product, design, and engineering. One PM, one designer, multiple engineers. The demand for product and designer time and bandwidth has always outpaced their capacity — that’s the mismatch. AI coding agents amplify it dramatically. If I’m now shipping 10x the code, the demand on my PM and designer to define requirements, review what I built, and stay aligned only grows. The gap widens.
This is why I think the triad has to be part of the new workflow — not just informed about it. And here’s what changed when I moved from code review to spec review: everyone can participate.
Code diffs are only for engineers — not for PMs, not for designers. But specs? Everyone can read specs. I start every feature by having AI interview me — one question at a time — until we have a thorough spec. This idea comes from Harper Reed’s LLM codegen workflow, published in February 2025 — before any of the coding agents included a planning mode. I have been following this religiously for 13+ months and modified it a bit (notably on TDD, which I covered above).
One-shot prompts don’t work for code. They also don’t work for specs. Don’t use them. The constraint-defining process is the thinking — that should not be outsourced.

Our PM reads the specs and gives feedback. Our devs review the spec before the PR. Our designer pairs with us during spec creation — we brainstorm together, build three versions, and iterate. The spec becomes the shared artifact where product, design, and engineering converge.
I’ll be honest — this doesn’t solve the 1:N mismatch. If anything, it makes it more visible because now the whole triad is expected to participate in spec reviews, and that’s more demand on PM and designer time. I don’t have a solution for that yet. It’s the next problem to figure out.
I read 200 lines of a spec instead of 2,000 lines of code. And honestly? I understand the system better now than when I was reviewing every line. Because the spec captures intent. Code only captures implementation. Bug comes in? The spec tells you the intent, the constraints, what was deferred.
People have a lot of different opinions about what code review is for. I like Blake Smith’s framing from Code Review Essentials for Software Teams — the most important function of code review isn’t catching style or bugs. It’s mental alignment. Keeping the team on the same page about how and why the code is changing. When AI writes most of the code, I need a new vehicle for that alignment. For me, that vehicle is specs.
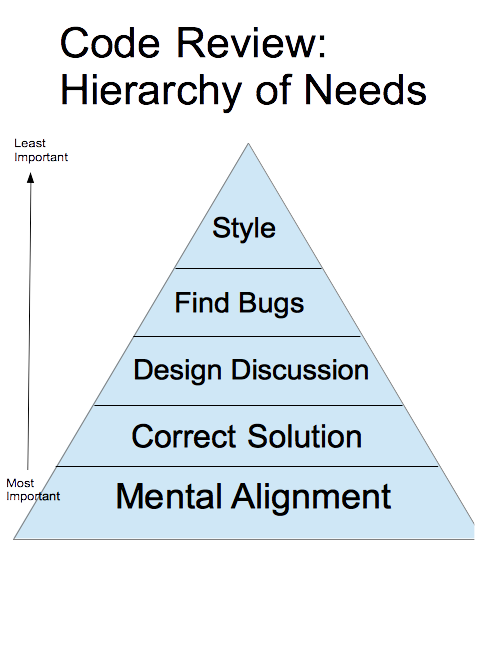
The scary part: cognitive debt
However, moving away from human reviews introduces a new challenge. And this is the part that I think people don’t talk about enough.
The real risk of AI-generated code isn’t bad code. It’s cognitive debt.
Technical debt is a term everyone knows — it lives in the code. The shortcuts, the workarounds, the design choices that make the system harder to change over time. You can see it, you can measure it, you can file tickets to fix it. Cognitive debt is different. It lives in my brain.
When AI writes all the code, I lose the plot. And I don’t mean the how — obviously I can ask Claude or Cursor to explain how something is implemented. Maintaining software isn’t the main challenge. Losing the plot means losing the what and the why. What does this system do? Why was it built this way? Why did we make that trade-off and not a different one? That mental model — the understanding of intent and design decisions — used to be a byproduct of code review. Every PR I reviewed, I absorbed a little more of the system’s story. Now that I’m not doing line-by-line code reviews, that byproduct is gone. And nothing automatically replaces it.
AI doesn’t remove the need for engineering rigor — it punishes the absence of it.
This is why specs matter so much. They’re the antidote. Specs are how I deliberately maintain the plot that I used to absorb passively through code review. When the spec captures intent, constraints, and trade-offs — and when the team reviews it — they also maintain the plot. They know why the system works the way it does, even if they didn’t write the code that implements it.
What I’m still figuring out
I’m not going to pretend I’ve figured everything out. There are real challenges I am actively working through.
Finding the right level of human-in-the-loop. What is the right level of abstraction to trust AI writing code, so I’m not reading code line-by-line? And what is the right level of abstraction to not let the team get bogged down with review but also not let them lose the plot of the system? These are questions I think about every day. Line-by-line review is one wrong extreme, zero review is the other, and the right answer is somewhere in between — and it’s probably different for every team, every codebase, every risk profile. I’m calibrating every week.
Spec drift. If specs fight cognitive debt, they have to stay current. A stale spec that tells you the wrong thing is worse than no spec at all. I am experimenting with compacting and summarizing specs after each release so the team stays aligned on the current state of the system. But unlike code — where the compiler keeps you honest — there’s no linter for an outdated spec. I’m still figuring this out.
The identity shift
I want to be honest. This is an awakening moment for me. I’m not writing code anymore. And giving up my code… that feels like giving up my identity as a developer. Giving up TDD felt like giving up my discipline.
I know it’s uncomfortable. I’m still in it.
But the old model — proving your worth by how many lines you can read and gatekeep — doesn’t scale when AI writes most of the code. I had to find a new way to add value.
The old metric: How close am I to the code? The new metric: How fast am I enabling my triad to ship and learn?
I stopped being a guardian of the code. I became a guardian of the intent.
My specs aren’t prompts I throw away — they’re how I fight cognitive debt. They’re the institutional memory of why I built what I built — not how.
The question isn’t whether I’ll use AI to write my code. That ship has sailed. The question — the right question — is how I build the workflows that let me still understand my systems when AI writes most of them.