RAG From Scratch – Research to Production
This series bridges the gap between AI research and software engineering. It moves from the high-level intuition of Large Language Models to the low-level systems engineering required to build deterministic, production-grade RAG pipelines.
- Part 1: Revolutionizing Question-and-Answer Systems (RAG Intuition) – The mental model of the “Student” and the “Librarian.”
- Part 2: Building RAG: All Things Retrieval – The basics of Vector Stores and Search.
- Part 3: Deep Dive: Keyword Search – Understanding BM25 and the math of “exact match.”
- Part 4: RAG Systems Engineering: The Structure-Aware Data Pipeline – Fixing the “Garbage In” problem with logical chunking.
- Part 5: Beyond Vectors: Sparse Embeddings & SPLADE – Solving the “Vocabulary Mismatch” problem.
- Part 6: RAG Architecture: The “Union + Rerank” Pipeline – Orchestrating Hybrid Search for production.
This first article sets the mental model for RAG: treating the LLM as the “Student” (reading comprehension) and your retriever as the “Librarian” (finding the exact page). It explains why fine-tuning struggles to add reliable facts and why RAG reframes Q&A as search + reasoning.
LLMs (large language models) are truly remarkable with their language understanding, comprehension, and creative writing skills. They are revolutionizing the way question-and-answer systems are built. During the training phase, you can consider that LLMs are compressing the world knowledge and storing it in the form of parameters, but also learn the language in the process. Although they captured the world knowledge in a compressed manner, this can be considered very lossy compression. When creating question-and-answer systems, it is important to note that due to this lossy compression during training, retrieving information may pose a challenge. However, LLMs’ language understanding is pivotal in accurately interpreting user’s question and producing text that is both syntactically and semantically correct.

The False Promise of “Teaching” the Model
How do we bridge this gap between the LLM’s general knowledge and our specific, unavailable data?
The intuitive first response is often: “Let’s just teach the model our data.”
If an employee doesn’t know the company handbook, you make them study it. In AI terms, this translates to attempting to bake new knowledge directly into the model’s parameters through training. There are generally two approaches to this:
-
Full Retraining: Training a model from scratch on your data. This is prohibitively expensive and impractical for most.
-
Fine-Tuning: Taking an already existing powerful model (like GPT-4 or Llama 3) and training it slightly further on your specific data.
Because full retraining is unrealistic, many turn to fine-tuning. While fine-tuning is excellent for teaching a model a specific task (like summarizing legal documents) or a specific style (like speaking like a pirate), it is notoriously unreliable for adding new knowledge for retrieval.
Why does fine-tuning fail for Q&A? We already discussed the “lossy compression” issue—even if you fine-tune, there is no guarantee the model retains the exact facts. But there is an even deeper issue.
The “Reversal Curse” of Fine-Tuning
Even if we choose to fine-tuning seems like the logical fix, we run into a fundamental limitation of how LLMs store knowledge known as the “Reversal Curse”.
LLMs do not store facts like a relational database. If an LLM is fine-tuned repeatedly on the sentence “Tom Cruise’s mother is Mary Lee Pfeiffer,” it will learn the statistical likelihood of those words appearing in that order. It will likely answer correctly if you ask “Who is Tom Cruise’s mother?”
However, if you ask “Who is Mary Lee Pfeiffer’s son?”, the model often fails to answer.
This happens because the model learned the probability of words in a specific sequence (A $\rightarrow$ B), but it did not deduce the logical relationship (B $\rightarrow$ A). This makes fine-tuning an unreliable method for retrieving specific facts, further strengthening the case for RAG, where we provide the exact bi-directional context explicitly.
As you may recall, LLMs are not only experts in language but also in knowledge. Since we can’t always rely on their knowledge, we can make use of their expertise in language. To illustrate this, let’s consider the task of reading comprehension. Having a strong grasp of the language enables someone to understand the given text and respond to questions in a grammatically correct and syntactically sound manner. Similarly, we can transform the problem of building a question-and-answer system into a reading comprehension system where LLMs are asked to provide answers using the context provided. This is essentially how a retrieval-augmented-generation system works; it leverages LLMs’ ability to comprehend provided text. Language models have large context windows that allow for embedding relevant text which LLMs can utilize to answer users’ questions.
A Note on Context Windows
The “Lost in the Middle” Phenomenon you might wonder: “If LLMs have massive context windows (millions of tokens), why do we need complex retrieval? Why not just paste the whole document into the prompt?”
While the context window can fit the text, the model’s ability to “comprehend” it is not uniform. Research shows a “Lost in the Middle” phenomenon where LLMs are great at retrieving information from the very beginning or the very end of the prompt, but their recall degrades significantly for information buried in the middle. RAG isn’t just about fitting data into the window; it’s about curating that data so the most important facts are front-and-center, ensuring the model actually “sees” them.
Retrieval Augmented Generation is very analogous to reading comprehension.
The Intuition: Language Skills vs. World Knowledge
To understand why RAG works, we need to distinguish between knowing a subject and knowing the language.
Think of a student in the 5th grade. By this age, they have acquired a specific level of language competency: they possess a working vocabulary, they understand grammar, and they can follow logical sentence structures.
Now, imagine giving this student two different reading comprehension tests.
Scenario A: The Microbiology Paper (Unknown Topic)
You hand the student a paragraph from a microbiology paper. The student has never studied microbiology; they don’t know what a “mitochondria” is.
-
The Task: Read this paragraph and answer: What is the function of the mitochondria described in the text?
-
The Result: The student can answer correctly.
-
Why? Not because they are a biologist, but because they have the Language Skills to parse the sentence structure (“The mitochondria functions as…”) and extract the answer.
This is the essence of In-Context Learning. The Pre-training phase of an LLM is like the student’s years of schooling—it teaches the model the structure of language and reasoning. RAG relies on the fact that if you have high language competency, you don’t need to have memorized the facts beforehand; you just need the facts presented in the context.
Scenario B: The Snow White Story (Known Topic)
Now, imagine you hand the student a passage from Snow White—a story she already knows by heart.
-
The Task: Read this specific passage and answer the question. Use ONLY the information in the passage.
-
The Challenge: This tests Instruction Following. Because the student already has the “World Knowledge” (the memory of the movie), she has to actively suppress that memory and strictly adhere to the constraints of the provided text.
Why this explains RAG
This analogy highlights the two engines of a RAG system:
-
Competency (Pre-training): The model doesn’t need to be trained on your private company data to understand it. It just needs the language competency to read it—which it acquired during its initial training (compression).
-
Constraint (Instruction Following): When we prompt a RAG model, we are effectively acting as the exam proctor, demanding that the model suppress its “Snow White” memories (hallucinations) and answer only using the “Microbiology packet” we just gave it.
This analogy reveals the fundamental shift RAG brings to conversational Q&A systems: We are transforming the task of Question-Answering from a Generative problem into a Search problem.
Instead of asking the model to remember facts (Generative), we are asking it to process facts we provide (Reasoning). This leaves us with two primary engineering goals for building a RAG system:
-
The Retrieval Challenge: Finding the exact ‘packet’ of information (the microbiology paragraph) within your private data.
-
The Grounding Challenge: Crafting instructions that force the model to stick strictly to that packet and ignore its training memory.
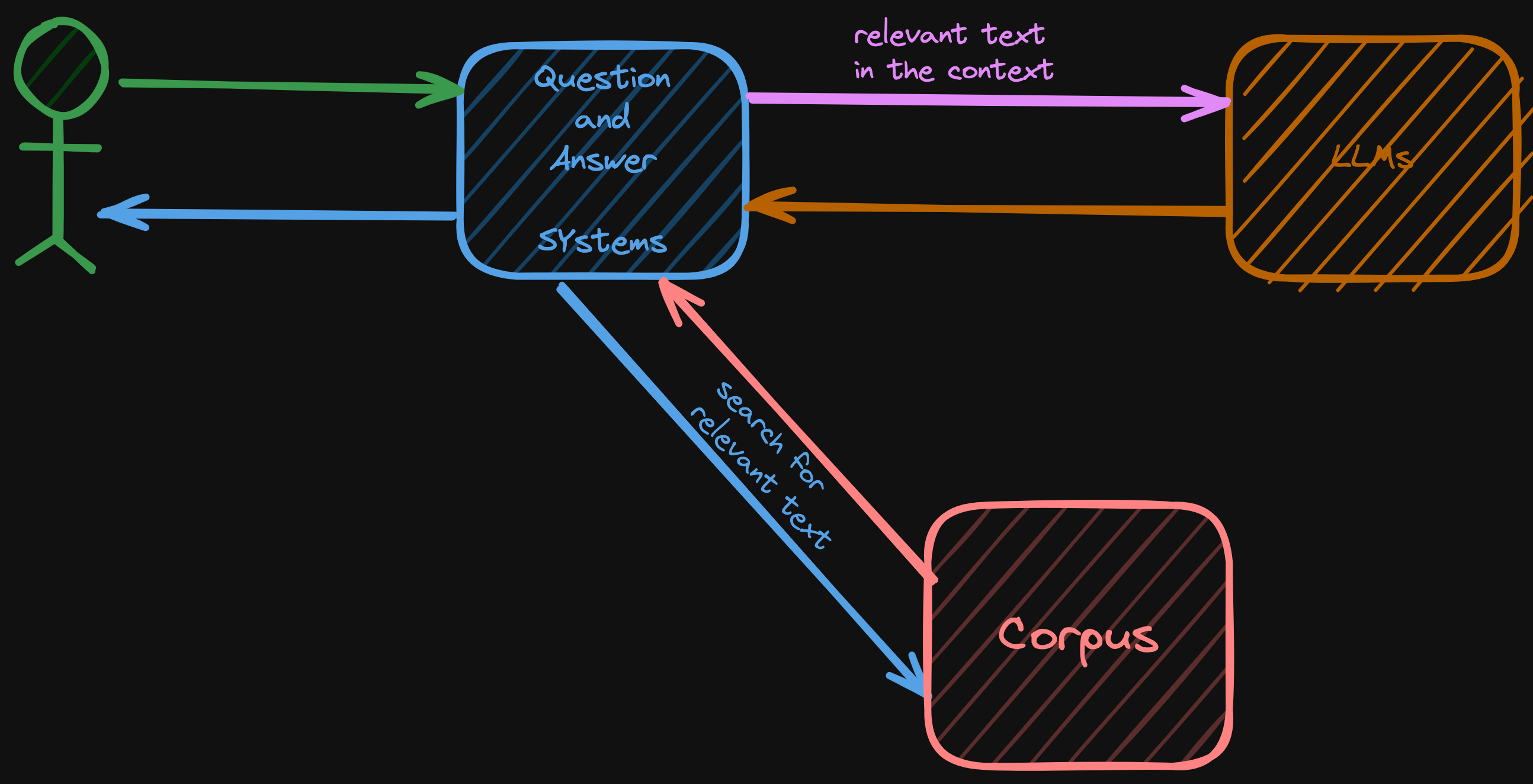
I will explain each of these two goals in a multi-part series.
Next up: Building RAG: All Things Retrieval — we translate the intuition into engineering by covering chunking strategies, search methods, and ranking. Read Part 2 here: Building RAG: All Things Retrieval.